AI/ML
Understanding RAG in Generative AI: How It Works and Why It Matters

Written ByYash Vibhandik
CEO, Bitontree
Published:3 April 2025
20 minutes read

From chatbots to automated content generation, AI applications are constantly changing the way we interact with technology and utilize them to transform operational workflows. Generative AI can write text, sketch images, and automate monotonous tasks, freeing professionals from completing less valuable and time-consuming tasks.
From chatbots to automated content generation, AI applications are constantly changing the way we interact with technology and utilize them to transform operational workflows. Generative AI can write text, sketch images, and automate monotonous tasks, freeing professionals from completing less valuable and time-consuming tasks.
Retrieval-Augmented Generation, or RAG, is the solution. RAG is an AI framework that improves the LLM response accuracy by giving the LLM access to external data sources. The LLM is trained on enormous datasets, but they lack the specific context about a business, industry, or customer. So, instead of letting LLM rely solely on pre-trained knowledge, RAG retrieves the relevant data from external sources before LLM generates a response.
According to IBM, Advanced RAG AI Models improves AI accuracy by 85%, making everything much more factual and trustworthy. With companies relying more heavily on AI, RAG will be a boon, as it guarantees well-timed decision-making and trustworthy outputs. Let's discuss how RAG works, its advantages, and why it's a game-changer in today's age of modern AI and Gen AI applications.
What is RAG?
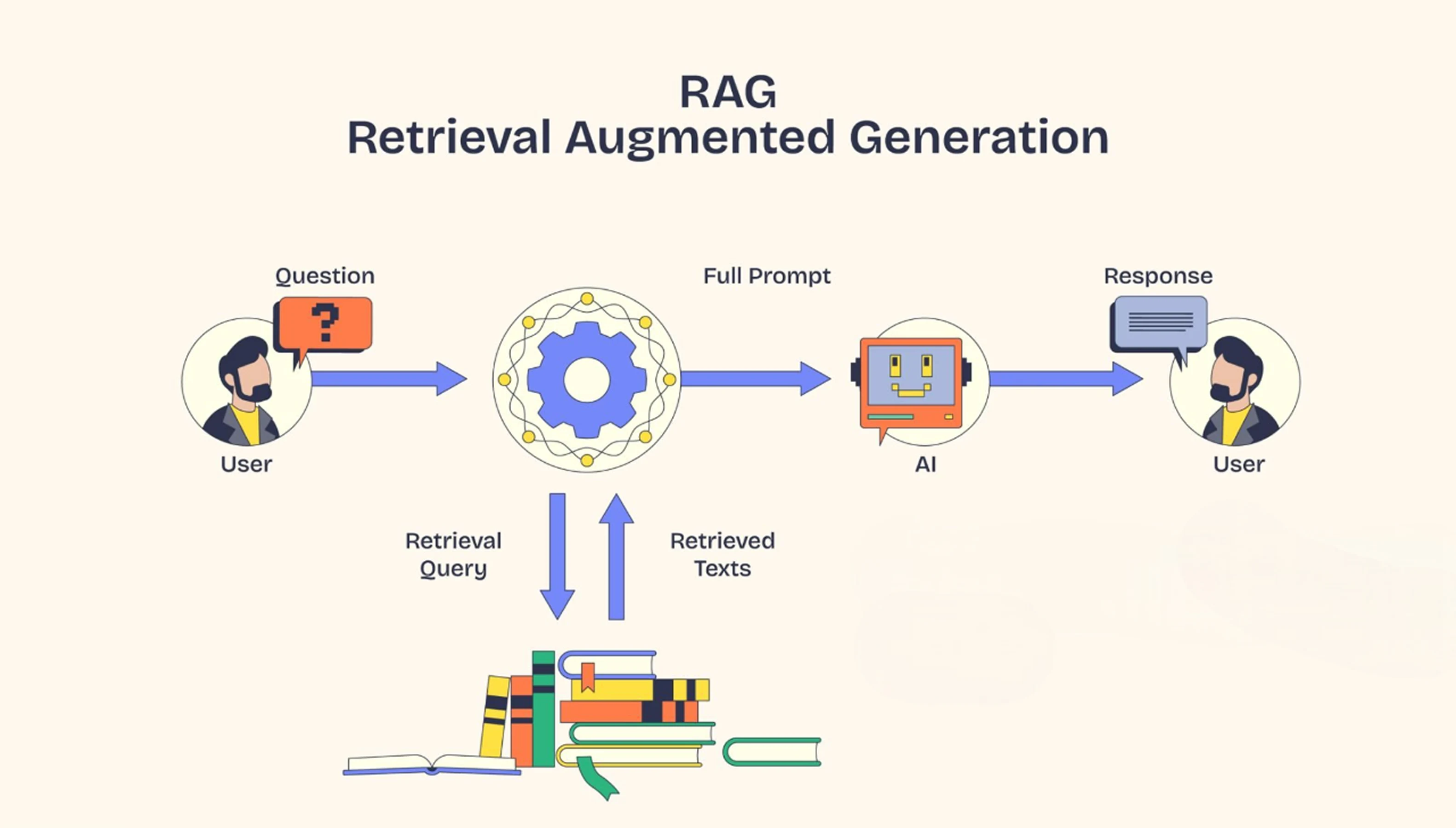
RAG is a technique that enhances the LLM’s capabilities to deliver accurate answers by incorporating real-time data retrieval. It allows the LLM to search external databases or documents during the output generation process to deliver accurate and up-to-date information.
Each RAG model has two major building blocks: the Retrieval Module and the Generation Module. The retrieval system searches through the extensive knowledge base and finds the most relevant information that matches the input sequence. This information is fed to the generative model, and it uses this to create a well-informed and accurate response.
According to a research paper, human evaluators found that RAG-based responses are 43% more accurate than LLM which solely relied on fine-tuning.
For instance, Meta’s RAG model is a differential end-to-end model that combines an information retrieval component (Facebook AI’s dense-passage retrieval system) with a seq-2-seq generator (Meta’s Bidirectional and Auto-Regressive Transformers [BART] model).
A neural retrieval system is an AI-based information retrieval method that uses deep learning models, especially neural networks, to retrieve relevant documents or passages based on a given query.
On the other hand, seq-2-seq is a deep learning architecture that converts one sequence into another of variable lengths. The seq-2-seq architecture is based on encoder and decoder components, where the encoder processes the input sequence into a fixed-length representation, and the decoder generates an output sequence based on this representation. The seq-2-seq architecture forms the foundation of LLMs designed for tasks such as machine translation, text summarization, chatbots, and question-answering.
The RAG model looks and acts like a seq-2-seq model; however, there is one intermediary step that makes all the difference. Instead of sending the input sequence to the generator, RAG uses the input to retrieve a set of relevant documents or information from a source, like Wikipedia.
So, the LLM based on RAG architecture supports two sources of knowledge: 1. Knowledge that the seq-2-seq model stores in its parameters (parametric memory) 2. Knowledge stored in the corpus through which RAG retrieves external information (non-parametric memory)
These two sources complement each other. The RAG architecture gives flexibility to LLMs that rely on a closed-book approach (pre-learned knowledge) to improve the accuracy of responses by integrating with models that follow the open-book approach (fetch real-time information from external sources).
For example, if a prompt “when did the first mammal appear on Earth” is searched, then the RAG looks for documents with “Mammal”, “History of Earth”, or “Evolution of Mammals”. These supporting documents are concatenated as the context with the original input, and it is fed to the seq-2-seq model to produce the output.
How Does RAG Work?
Retrieval Augmented Generation uses entirely different forms of outside knowledge to enhance an AI-generated response. In contrast to former models, which were heavily reliant on pre-trained data, RAG dynamically retrieves relevant information before generating an answer. Accuracy, therefore, improves while the rate of misinformation is effectively reduced. According to Meta AI, RAG has improved response precision by over 60% as opposed to normal generative models. This is how it works:
Step 1: Understanding Query
- Firstly, the model takes the input query from the user.
- It understands the key intent, keywords, and context by applying Natural Language Processing (NLP) methods.
Step 2: Information Retrieval
- Searching for relevant information from outside knowledge bases like Wikipedia, databases, or private documents.
- It does not just rely on dense retrieval using vector embedding techniques to extract contextually relevant documents.
- Advanced techniques such as FAISS (Facebook AI Similarity Search) and BM25 improve the search efficiency.
Step 3: Context Integration
- The documents retrieved have been processed and ranked for relevance.
- Content retrieved through this process is grouped with the self-originated user query to form an enriched input.
- Important data are refined and weighted by the self-attention mechanisms of transformer models.
Step 4: Response Generation
- The generative model, usually a transformer-based architecture such as GPT-4, uses this enriched context to generate an answer.
- Reduces hallucination and provides real-time, fact-based answers.
Step 5: Output Delivery
- The post-processing algorithm is a means for adjusting the ultimate result to the human ends of its expression.
- As a result, the system responds with a very well-sourced, accurate, and context-based answer.
Retrieval-augmented generation keeps and updates the AI models such that, with context accuracy critical for application-based ones in financial, healthcare, and legal research, it becomes a combination of retrieval and generation.
Key Benefits of RAG
The main goal of retrieval-augmented generation (RAG) is to increase the dependability of any AI solution for the internal processes of text creation and information retrieval. As RAG actively retrieves its pertinent knowledge to achieve significantly better accuracy, transparency, and scaling, the much-lauded older generation's paradigm has recently proven to be insufficient.
50% of the overall accuracy gained in AI fact-free text may be required for retrieval augmentation to address the vast sectors of healthcare, finance, and legal research. These are the main benefits:
1.) Enhanced Accuracy
RAG is current and incorporates verifiable factual data immediately before it generates a response. For example, RAG for medical AIs will get validated studies from databases like PubMed so that it doesn't end up providing a false recommendation.
2.) Dynamic Knowledge
RAG has real-time access through API calls and other such dynamic sources to present information on contemporary facts. This is a crucial feature for areas requiring real-time updates like financial forecasting or valuable alerts in case of security incidents.
3.) Scalabilty
RAG is capable of dealing with massive ambiguity from complicated queries, bringing information in from very large sources, synthesizing it, and then making it available as an answer. In addition to this, it saves on computing resources since it only retrieves the relevant documents but avoids or reduces the need to generate whole responses from scratch. For example, RAG will help provide updated product information so that an e-commerce customer may find out about current pricing and availability.
4.) Transparency
Together with source traceability of the data that is retrieved, RAG gives a transparency absent with the black-box AI. It adds to the trust with such specialized institutions as law and finance, which carry with them strict regulatory requirements.
5.) Context Awareness
All user history and contextual information are retained in RAG for user-like floating conversation. It enhances response precision through references to earlier interactions and improves AI-powered customer support.
6.) Adaptive Learning
The self-updating mechanism of RAG makes it better in retrieval and generation with timely feedback. It fits a chatbot, AI-powered research tool, and other artificial intelligence programs. It is this synchronism with retrieval and generation that adds to RAG's differentiation from the rest in a new paradigm in accuracy, efficiency, and real-time adaptation of AI.
Applications of RAG
Retrieval-augmented generation (RAG) is changing the landscape of AI applications by presenting a whole new vista for improvements in accuracy, efficiency, and real-time adaptability. Unlike normal generative models, it makes use of data that can collaboratively be verified prior to the actual generating phase, which makes it economical in industries with higher demands for accuracy.
Even the AI retrieval model can improve response accuracy by a whopping 55% by guaranteeing factual consistency across organizations. Here are some applications of RAG:
Question Answering Systems

AI-powered chatbots and virtual assistants are spurred on by RAG, making it able to produce a relevant answer in real-time. Unlike the classical AI system, it cross-references facts from various sources to improve the quality of its answer. An example of the RAG integration used by Bard from Google and ChatGPT is in providing trained, accurate answers with citations.
Content Creation

RAG is the silent working partner of writers, journalists, and researchers in retrieving confirmed information for fact-checking. This allows the cross-referencing of content generation across multiple databases, thus reducing the chances of misinformation. The leading tool of this generation is Jasper, which uses RAG to suggest contextual content to work on.
Customer Support

RAG enhances AI-induced customer support through solid retrieval of factually consistent data about products. It also personalizes a response based on user history and external knowledge. The e-commerce support bot uses this to retrieve the current order status and refund policy information for the logged-in user.
Faster Information Retrieval

RAG has the ability to index and retrieve a diverse range of content types, including text, images, audio, and videos. This makes a RAG an intelligent integration in the university workflow with diverse resources. Students can easily get the desired study material, resources, and information from a single integrated platform.
Healthcare Data Extraction

RAG can be used in the healthcare industry to extract and synthesize relevant information from comprehensive medical databases, electronic health records, and research repositories. Traditional LLMs, like pure generative models or rule-based systems, cannot sustain because they often lack the capabilities to tailor the output on the basis of context.
However, RAG extracts the relevant information from the sources and tailors the outcome. Also, the use of proprietary data helps in providing personalized insights for the patients.
Challenges and Limitations
Retrieval-augmented generation, or RAG, of course, improves the accuracy and relevance of AI, but at the same time, it comes with some technical and operational bottlenecks. With low latency constraints, it's computationally very intensive and requires the most careful optimization of retrieval and handling of bias consideration in implementing re-augmented generation.
According to Stanford AI Research, retrieval-based models consume 40% more computing power than normal generative models, sealing an end to the engineering capability to tolerate some processing load. Scaling is still an issue, some of the most noticeable problems include:
The Computational Complexity of the Process
As retrieval and generation entail RAG, this means a doubling of processing power and memory requirements. Large-scale data require high-end processing systems such as GPUs, TPUs, or distributed computing frameworks for handling. Even training RAG models such as OpenAI's GPT with retrieval layers incur cloud computing costs of several million dollars.
The Quality of Knowledge in the Base
As it depends on outside sources, RAG is directly susceptible to faulty and old information. Secondary updating and curation of domain-specific datasets from which the RAG System can draw anchor answers must, therefore, be sustained for operational reliability. When RAG is used in a finance chatbot, it may misquote based on obsolete market data.
Bias and Fairness
Data retrieved can encapsulate biases from their sources. Neutralization is reinforcement learning plus human efforts. Hence, AI-generated legal recommendations would invariably be biased for cases that are trained on a biased case law-based database.
Latency
RAG models would be slow because they would need to retrieve and process data before generating a response. Improvements in indexing algorithms and retrieval speed will, therefore, continuously pose unique challenges for real-time applications. AI-based tools for medical diagnosis would not work in emergencies because of the speed delays in retrieval.
Though challenges persist, the progress in the infrastructure of AI, improved retrieval performance, and the methods to curb bias would enable some of the setbacks to come into light, promising high-precision applications in AI.
Future of RAG
Retrieval-augmented generation (RAG) is a field that is rapidly growing into an area of research where the search for technologies and applications promises smarter, more flexible, and fairer artificial intelligence systems. The needs of the time place a huge demand on real-time AI responses to increase the processing, and scientists would explore all possible avenues, from better retrieval systems to multimodal fusion and personalization
Integration with Multimodal AI
Next-generation RAGs are expected to understand multimodal input by processing and simultaneously generating Python responses, threading another layer into the fabric of the human-AI interaction tapestry for richer experiences.
Thus, voice-led assistants analyzing visual data will augment experiences in AI, for example, through an AI medical assistant looking at patient images and cross-referencing those after clinical notes and lab reports for diagnostic accuracy.
Advancements in Retrieval Techniques
Neural retrieval models will ensure context-based, accurate ranking of retrieved documents. Simultaneous updates would further troubleshoot the knowledge integration with less static datasets with dynamic updates at a lower maintenance cost. Financial AI assistants would now show live market trends for stocks and not stale trends.
Personalization
AI will personalize responses to users based on interaction history, preferences, and modes of interaction and interface. This will make the experience more engaging and efficient, putting the user in control. E-learning platforms will give their explanation according to the previous interaction of a student with them
Ethical Considerations
AI should permit the bias-free and responsible application of RAG systems; explainability tools, on the other hand, will promote transparency in the decision-making process, thus reducing AI-associated risks. Such tools should quote diverse, unbiased sources to ensure legal AI dispenses just legal advice. Further, with retrieval efficiency, multimodal AIs, and ethical AI frameworks, RAG looks set to evolve and redefine intelligent automation in different industries.
Conclusion
Retrieval-Augmented Generation, or RAG, is an advancement in developing Generative AI, which gives accuracy through real knowledge retrieval. Hallucinations are minimized, the relevance of responses to queries is maximized, and access to external data is dynamic in this model, unique from others. This has built a tension bridge between creative generation and knowledge retrieval, making AI meaningful and contextual.
Advances in AI today will also force companies and researchers to think beyond the RAG space application for content creation, customer support, and decision framing. With RAG, organizations will develop intelligent and more efficient AI systems for a competitive edge. Now is the time to invest in RAG-powered AI for a smarter digital future!
Share This Blog




Transform AI with RAG – Get Smarter, More Relevant Outputs!
Related Blogs



Frequently Asked Questions
It combines retrieval (fetching relevant data) and generation (creating responses), ensuring outputs are factually grounded, reducing hallucinations, and making AI more context-aware.
RAG helps businesses by providing real-time, accurate information from external knowledge bases, making AI-powered customer support, document automation, and decision-making more reliable.
RAG is used in automated research assistants, AI-powered search engines, chatbot enhancements, medical diagnosis tools, and personalized recommendation systems.
Unlike standard models that rely solely on pre-trained data, RAG dynamically pulls information from external sources, reducing outdated or incorrect responses.
